 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDo Agents Need Semantic Metadata? A Comparative Study in Agentic Data Retrieval
May 27, 2026In the era of autonomous agents, machine-actionable data is critical for data-driven workflows. For more than a decade, semantic metadata like schema.org has anchored the FAIR principles (Findable, Accessible, Interoperable, and Reusable) for machine-actionable data and enabled discovery tools like Google Dataset Search. However, the rise of Large Language Models (LLMs) capable of navigating the unstructured web raises a fundamental question: Is semantic metadata still necessary for agentic data discovery, or can agents reliably retrieve actionable data directly from the web? We present a comparative analysis of agentic data retrieval across two distinct environments: a Baseline Agent searching billions of open-web documents, and a Semantic Agent leveraging a corpus of 90 million datasets using schema.org. We deploy an "LLM-as-a-judge" evaluation pipeline, mapped directly to the FAIR principles, to assess the semantic relevance, data accessibility, and computational utility of the retrieved data. Our results reveal a clear divergence. The Semantic Agent excels at retrieving actionable data, achieving a 44.9% higher precision for metadata-rich registries and a 46.6% higher precision for pages with machine-readable downloads among its returned results. Conversely, the Baseline Agent frequently suffers "Last-Mile Utility" failures, retrieving prose-heavy pages (20.1% of results) and portal landing pages (8.5%) rather than actual data pages. While the Baseline Agent achieves higher coverage by answering 40% more questions, the Semantic Agent delivers greater accuracy, achieving 65.7% higher overall precision in retrieving FAIR-compliant datasets. We conclude that while unstructured retrieval supports broad exploratory tasks, structured ecosystems remain the indispensable foundation for reliable, execution-oriented autonomous workflows.
100x Cost & Latency Reduction: Performance Analysis of AI Query Approximation using Lightweight Proxy Models
Mar 16, 2026Several data warehouse and database providers have recently introduced extensions to SQL called AI Queries, enabling users to specify functions and conditions in SQL that are evaluated by LLMs, thereby broadening significantly the kinds of queries one can express over the combination of structured and unstructured data. LLMs offer remarkable semantic reasoning capabilities, making them an essential tool for complex and nuanced queries that blend structured and unstructured data. While extremely powerful, these AI queries can become prohibitively costly when invoked thousands of times. This paper provides an extensive evaluation of a recent AI query approximation approach that enables low cost analytics and database applications to benefit from AI queries. The approach delivers >100x cost and latency reduction for the semantic filter (AI.IF) operator and also important gains for semantic ranking (AI.RANK). The cost and performance gains come from utilizing cheap and accurate proxy models over embedding vectors. We show that despite the massive gains in latency and cost, these proxy models preserve accuracy and occasionally improve accuracy across various benchmark datasets, including the extended Amazon reviews benchmark that has 10M rows. We present an OLAP-friendly architecture within Google \textit{BigQuery} for this approach for purely online (ad hoc) queries, and a low-latency HTAP database-friendly architecture in \textit{AlloyDB} that could further improve the latency by moving the proxy model training offline. We present techniques that accelerate the proxy model training.
30DayGen: Leveraging LLMs to Create a Content Corpus for Habit Formation
May 02, 2025In this paper, we present 30 Day Me, a habit formation application that leverages Large Language Models (LLMs) to help users break down their goals into manageable, actionable steps and track their progress. Central to the app is the 30DAYGEN system, which generates 3,531 unique 30-day challenges sourced from over 15K webpages, and enables runtime search of challenge ideas aligned with user-defined goals. We showcase how LLMs can be harnessed to rapidly construct domain specific content corpora for behavioral and educational purposes, and propose a practical pipeline that incorporates effective LLM enhanced approaches for content generation and semantic deduplication.
Human-Centered Planning
Nov 08, 2023



LLMs have recently made impressive inroads on tasks whose output is structured, such as coding, robotic planning and querying databases. The vision of creating AI-powered personal assistants also involves creating structured outputs, such as a plan for one's day, or for an overseas trip. Here, since the plan is executed by a human, the output doesn't have to satisfy strict syntactic constraints. A useful assistant should also be able to incorporate vague constraints specified by the user in natural language. This makes LLMs an attractive option for planning. We consider the problem of planning one's day. We develop an LLM-based planner (LLMPlan) extended with the ability to self-reflect on its output and a symbolic planner (SymPlan) with the ability to translate text constraints into a symbolic representation. Despite no formal specification of constraints, we find that LLMPlan performs explicit constraint satisfaction akin to the traditional symbolic planners on average (2% performance difference), while retaining the reasoning of implicit requirements. Consequently, LLM-based planners outperform their symbolic counterparts in user satisfaction (70.5% vs. 40.4%) during interactive evaluation with 40 users.
Factuality Challenges in the Era of Large Language Models
Oct 10, 2023The emergence of tools based on Large Language Models (LLMs), such as OpenAI's ChatGPT, Microsoft's Bing Chat, and Google's Bard, has garnered immense public attention. These incredibly useful, natural-sounding tools mark significant advances in natural language generation, yet they exhibit a propensity to generate false, erroneous, or misleading content -- commonly referred to as "hallucinations." Moreover, LLMs can be exploited for malicious applications, such as generating false but credible-sounding content and profiles at scale. This poses a significant challenge to society in terms of the potential deception of users and the increasing dissemination of inaccurate information. In light of these risks, we explore the kinds of technological innovations, regulatory reforms, and AI literacy initiatives needed from fact-checkers, news organizations, and the broader research and policy communities. By identifying the risks, the imminent threats, and some viable solutions, we seek to shed light on navigating various aspects of veracity in the era of generative AI.
Reimagining Retrieval Augmented Language Models for Answering Queries
Jun 01, 2023



We present a reality check on large language models and inspect the promise of retrieval augmented language models in comparison. Such language models are semi-parametric, where models integrate model parameters and knowledge from external data sources to make their predictions, as opposed to the parametric nature of vanilla large language models. We give initial experimental findings that semi-parametric architectures can be enhanced with views, a query analyzer/planner, and provenance to make a significantly more powerful system for question answering in terms of accuracy and efficiency, and potentially for other NLP tasks
NormBank: A Knowledge Bank of Situational Social Norms
May 26, 2023



We present NormBank, a knowledge bank of 155k situational norms. This resource is designed to ground flexible normative reasoning for interactive, assistive, and collaborative AI systems. Unlike prior commonsense resources, NormBank grounds each inference within a multivalent sociocultural frame, which includes the setting (e.g., restaurant), the agents' contingent roles (waiter, customer), their attributes (age, gender), and other physical, social, and cultural constraints (e.g., the temperature or the country of operation). In total, NormBank contains 63k unique constraints from a taxonomy that we introduce and iteratively refine here. Constraints then apply in different combinations to frame social norms. Under these manipulations, norms are non-monotonic - one can cancel an inference by updating its frame even slightly. Still, we find evidence that neural models can help reliably extend the scope and coverage of NormBank. We further demonstrate the utility of this resource with a series of transfer experiments.
Multimodal Neural Databases
May 02, 2023



The rise in loosely-structured data available through text, images, and other modalities has called for new ways of querying them. Multimedia Information Retrieval has filled this gap and has witnessed exciting progress in recent years. Tasks such as search and retrieval of extensive multimedia archives have undergone massive performance improvements, driven to a large extent by recent developments in multimodal deep learning. However, methods in this field remain limited in the kinds of queries they support and, in particular, their inability to answer database-like queries. For this reason, inspired by recent work on neural databases, we propose a new framework, which we name Multimodal Neural Databases (MMNDBs). MMNDBs can answer complex database-like queries that involve reasoning over different input modalities, such as text and images, at scale. In this paper, we present the first architecture able to fulfill this set of requirements and test it with several baselines, showing the limitations of currently available models. The results show the potential of these new techniques to process unstructured data coming from different modalities, paving the way for future research in the area. Code to replicate the experiments will be released at https://github.com/GiovanniTRA/MultimodalNeuralDatabases
Learnings from Data Integration for Augmented Language Models
Apr 10, 2023One of the limitations of large language models is that they do not have access to up-to-date, proprietary or personal data. As a result, there are multiple efforts to extend language models with techniques for accessing external data. In that sense, LLMs share the vision of data integration systems whose goal is to provide seamless access to a large collection of heterogeneous data sources. While the details and the techniques of LLMs differ greatly from those of data integration, this paper shows that some of the lessons learned from research on data integration can elucidate the research path we are conducting today on language models.
Building Human Values into Recommender Systems: An Interdisciplinary Synthesis
Jul 20, 2022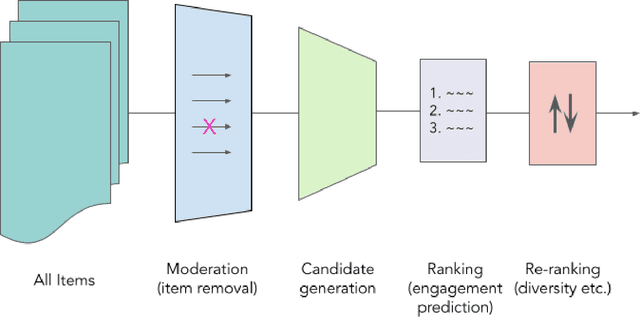
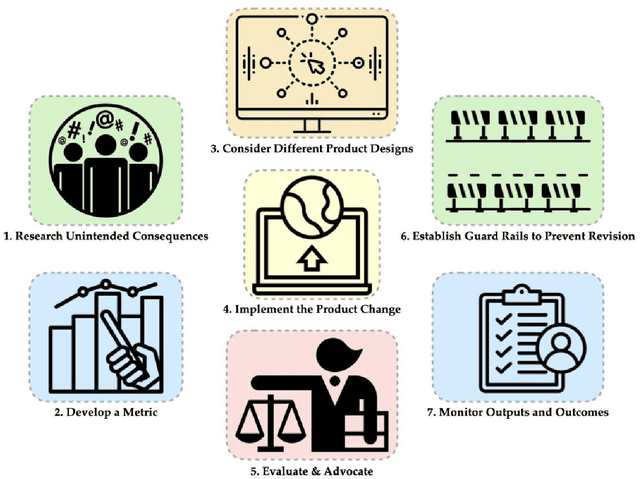
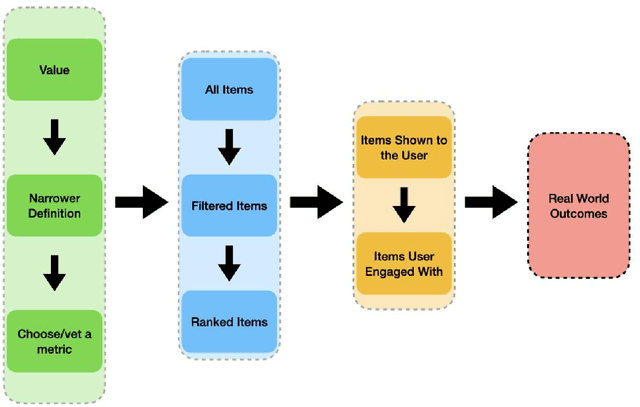

Recommender systems are the algorithms which select, filter, and personalize content across many of the worlds largest platforms and apps. As such, their positive and negative effects on individuals and on societies have been extensively theorized and studied. Our overarching question is how to ensure that recommender systems enact the values of the individuals and societies that they serve. Addressing this question in a principled fashion requires technical knowledge of recommender design and operation, and also critically depends on insights from diverse fields including social science, ethics, economics, psychology, policy and law. This paper is a multidisciplinary effort to synthesize theory and practice from different perspectives, with the goal of providing a shared language, articulating current design approaches, and identifying open problems. It is not a comprehensive survey of this large space, but a set of highlights identified by our diverse author cohort. We collect a set of values that seem most relevant to recommender systems operating across different domains, then examine them from the perspectives of current industry practice, measurement, product design, and policy approaches. Important open problems include multi-stakeholder processes for defining values and resolving trade-offs, better values-driven measurements, recommender controls that people use, non-behavioral algorithmic feedback, optimization for long-term outcomes, causal inference of recommender effects, academic-industry research collaborations, and interdisciplinary policy-making.